

Preface #
Next semester marks the start of the graduate school nomination season. Looking back at the past three years, I’ve certainly been a “tinkerer.” Some of these trials and errors are already starting to blur in my memory. I’m using the quiet of this winter break to document these fragments—partly as a keepsake, and partly as raw material for my personal statement.
Frustration
I’ve tinkered a lot, but “successes” are surprisingly rare. Writing a resume is genuinely painful. 😭
Before University #
First Impressions of ChatGPT #
Before the Gaokao (College Entrance Exam), our class used to watch the evening news on the classroom’s electronic whiteboard after dinner. That was the first time I heard the term: ChatGPT.
One data chart left a deep impression on me: a comparison of the time it took for electricity, mobile phones, the internet, and ChatGPT to reach a certain user milestone. Even though I felt the comparison wasn’t entirely rigorous—ChatGPT’s growth relied heavily on the pre-existing infrastructure of the internet—the “right-angle” spike of its user growth was staggering.
A seed was planted. I was curious about how it worked. Before ChatGPT, my impression of AI was limited to facial recognition and AlphaGo; I never imagined it could converse so naturally.
Tutoring #
During the post-Gaokao summer, boredom set in. Games I usually loved became tedious within days. At a classmate’s suggestion, I spent a month as a tutor, teaching chemistry to a student transitioning from middle to high school.
The kid was a “typical” Chinese student: no real interest in knowledge, just told by parents and school to get high scores. His parents were ordinary, kind, and slightly “Zen” about his future—perhaps having lost their edge after years of seeing his performance. The experience ended quietly, and I earned my first “bucket of gold.”
I still think about that kid. He made me ask: Why don’t kids today like learning? Or more broadly, why do we learn?
Neither the kids nor the parents seem to have a satisfying answer. “For a good university,” “for a good job,” “for a better life…” These aren’t wrong, but they explain one abstract concept with another. What is a “good” job? What defines a “better” life? Most kids only know that TikTok and Bilibili are fun, and “life” is just eating three meals and watching TV with parents.
Knowledge has never solved a problem for them or made their lives easier. Its only utility is the brief relief that follows a high test score. And it’s only brief, because the next exam is always around the corner. Learning was meant to be a tool for solving problems, but now learning itself has become the problem. When the means become the end, the motivation is doomed to be unsustainable.
Through these experiences, I’ve come to a realization about motivation: it comes from solving problems—any problem. If a child sees something as a problem worth solving, they will naturally seek out the knowledge needed to tackle it. If they value scores, they’ll learn how to analyze papers and optimize study habits. If they don’t, let them solve something else first. The confidence gained from solving any problem becomes the foundation for everything else.
Of course, I wasn’t this enlightened back then. I was dealing with my own greatest setbacks: failing the Physics Competition and underperforming on the Gaokao (largely due to a high fever from a COVID reinfection). These were choices I made myself. I had ignored my family’s advice to pursue the Physics Competition—a path less traveled and far more treacherous than the standard curriculum.
Reflection
This is likely why “involution” (internal competition) starts so young. Once people taste the advantage of “getting a head start,” they can’t resist. The superiority of crushing peers and the fear of being crushed are the twin engines of this cycle.
I tried to find some stability in books. In the second half of 2023, I logged 253 hours on WeChat Reading. I read everything: sci-fi, political economy (Das Kapital), programming languages, operating systems, business management, psychology, and biographies. I even tackled the Princeton Calculus Analysis and The Feynman Lectures on Physics. I clearly still loved physics, but the competition failure made me realize that physics is a field for geniuses—it requires quality over quantity. From a career perspective, Computer Science felt like a safer bet.
Note
My interest in physics lies in how it is both immensely complex and beautifully simple. Complex in its phenomena, simple in its mathematical intuition. By solving countless problems, I learned to build mappings between different fields to find new perspectives—often the key to breaking a deadlock.
Freshman Year #
Tinkering with a Personal Blog #
As I stepped into university life, my skill tree began to branch out.
Step one: bypassing the Great Firewall. This unlocked GitHub, Google, and a whole new world. I won’t go into details, but it was a gateway drug. I spent my time juggling coursework, setting up C/C++ environments in VSCode, drafting my blog, and cramming for English exams.
Looking back, my first blog tech stack was “green.” It was just a static resume template—the classic trio of HTML, CSS, and JavaScript. To post, I had to manually edit HTML and push to GitHub Pages. My domain was a clunky morethan987.github.io.
I gave up on a custom .cn domain after seeing the registration fees. I figured if only people with a VPN could see it, so be it; it wasn’t like I expected a huge audience anyway.
Side Note
If you’re reading this, you’re on the new blog. 🤣 The evolution is obvious.
Despite the inconveniences, I spent hours polishing the details: icons, new pages, glassmorphism designs, and light/dark mode toggles. It was my first “real” project: building a platform to publish my thoughts.
However, the experience was miserable. Editing HTML to write prose is a productivity killer. I knew my patience would eventually run out, and the site would become another “internet ruin.”
This project taught me the importance of Code Quality and Architecture. Good design frees you from the “maintenance trap,” allowing you to focus on what matters. I realized that rather than relying on willpower, it’s better to spend time lowering the cost of maintenance. That’s the principle of compound interest—do things that have long-term benefits.
Rant
This is why I’ve always disliked exams. After months or years of study, the knowledge suddenly loses its “value” the moment the timer hits zero. I’m not denying the “thinking skills” or the doors exams open, but the specific details we etch into our brains often vanish from our lives after the final bell. In the adult world, “selection” often trumps “cultivation.” I choose to tinker and try “inefficient” things because they make me feel like a human, not a mass-produced part.
Self-Teaching Machine Learning #
Winter break gave me time to explore my interest in Large Language Models (LLMs). I had zero foundation in ML, but my linear algebra was solid. I started an impromptu journey: reading Dr. Jiang’s Iris Book series, the classic “Deep Learning” (the Flower Book), and building a simple neural network from scratch using only NumPy. I even delved into neuroscience with A Thousand Brains and used ChatGPT to learn the Transformer architecture, aided by the Transformer Explainer website.
By the end of the break, I had a blurry intuition of how Transformers worked. I remember feeling a sense of dissonance—this architecture felt nothing like a biological brain. Most importantly, it couldn’t “continually learn.”
Influenced by A Thousand Brains, I began wondering how to build AI based on biological principles. My logic was simple: humans are the only known general intelligence, so what else is there to reference? I started reading papers on cortical columns, Global Workspace Theory, the hippocampus, and Spiking Neural Networks (SNNs).
The more I read, the more I realized the gap between neuroscience and AI is a chasm. Yet, I clung to this “biomimetic” fantasy. I once tried to treat neuron weights as part of the loss function, theorizing that biological neurons require energy to maintain strong connections. I later learned from an AI that I had independently “discovered” L 1 Regularization.
Reflection
It’s not much to brag about, but discovering regularization through my own logic gave me a much deeper understanding of the “why” behind the math.
Mathematical Modeling #
My schedule was packed with English exams and modeling competitions. Research was relegated to reading WeChat blog posts in my spare time.
The Mathematical Modeling competition felt tailor-made for me. The models were like simpler versions of physics competition problems. Still, our first mock trial was a mess. Modeling isn’t just about accuracy; it’s about whether the model can be coded and optimized.

We eventually settled on a “Power Team” structure. My teammate and I, both having physics backgrounds, handled the modeling and coding, while a third teammate did the illustrations. We specialized in “Problem A” (optimization).
Our toolchain became: LaTeX (via Overleaf) for typesetting and MATLAB for computation. Our workflow: spend the first few hours scouring literature. If you find a relevant paper, you’ve won half the battle. (For more details, see my MCM/ICM Summary).
Recommendation
I highly recommend Professor Xue Dingyu’s MATLAB Solutions to Higher Applied Mathematics Problems. It is incredibly detailed, especially the cross-comparisons of different algorithms.
We also “templated” everything. Why do the work during the competition if you can do it before? I wrote a rigorous LaTeX template with detailed comments and prepared a library of optimization scripts.
Winning the National Second Prize taught me the “Geek Spirit”: extreme focus, extreme efficiency, extreme optimization. It’s an addictive feeling when everything you’ve learned converts directly into results.
Dive into Deep Learning #
Regarding my journey into AI, while keeping up with the trending papers pushed by WeChat official accounts, I was also following Dive into Deep Learning and other resources to master classic model architectures from the pre-Transformer era, while further solidifying my foundational knowledge and implementation skills in deep learning.
What impressed me most were the principles of translation invariance and locality in Convolutional Neural Networks (CNNs). These two principles clearly illustrate the transition from fully connected networks to CNNs: leveraging the inherent structures within natural images to optimize the parameter efficiency of the neural network.
Thinking🤔
This phenomenon directly demonstrates that improvements in network architecture can lead to higher parameter efficiency. But is the CNN truly the most efficient architecture for image data? Does this imply that model architecture and parameter efficiency are two sides of a balanced seesaw? We could invest massive amounts of data, parameters, and compute to make a fully-connected network achieve better results, but we could also allocate a portion of that compute and those parameters toward architectural optimization to boost parameter efficiency. However, it seems that current Neural Architecture Search (NAS) is still limited to the coarse-grained permutation of modules. Perhaps a more fine-grained search method, combined with reinforcement learning, is needed to enable machines to autonomously design architectures that surpass human capabilities.
As for the posts on WeChat, my reading became quite superficial. Initially, I would occasionally read them carefully, but later I only skimmed the general ideas of the papers. On one hand, the impressions were fleeting and I remembered very little; on the other hand, many papers were quite far removed from my own line of thinking at the time. In my view, current large models are already performing exceptionally well—if they could only learn efficiently from real-time interaction, I wouldn’t ask for anything more. At the time, I was still wrestling with how to extract key inspirations for continual learning from the working mechanisms of the human brain, but that path was undeniably arduous.
Sophomore Year #
Blog Tech Stack Upgrade #
After the major allocation process, I transitioned from the undergraduate academy to the School of Computer Science and Engineering as a Computer Science and Technology major, becoming a traditional, “orthodox” CS student. With a new dormitory and new friends, I began studying more professional computer science knowledge and participated in a three-day national mathematical modeling competition with my teammates; all of this alongside daily coursework and preparation for my second attempt at the English CET-6.
The pain points of my original blog were, as mentioned before, simply too numerous. Consequently, I was constantly on the lookout for a new tech stack that could align with my writing habits while remaining easy to manage and maintain—and if performance could be improved further, that would be even better. I was extremely fortunate to discover Hugo, which fits my criteria almost perfectly: it uses Markdown for content creation and automatically compiles it into HTML. I chose the Blowfish theme, which features detailed documentation, is easy to configure, and supports high customization with a rich feature set and elegant aesthetics. Plus, the build speed is incredibly fast. Combined with GitHub Actions, I can achieve automatic push-updates, realizing a Git-triggered automated web blog deployment. For details, see Hugo Blog Setup.
However, the one slight drawback was that the syntax of Obsidian, which I use daily, has certain discrepancies with Hugo’s syntax, and I also needed to consider image copying and standardized folder structures. I wanted to be able to fully control the blog deployment process from within Obsidian, but after scouring the plugin marketplace, I couldn’t find one that fully met my needs. Thus, I decided to develop my own Obsidian plugin: Plugin Development.
Initially, this plugin utilized pure Regular Expressions for string replacement, but the resulting code was highly coupled. Different conversion processes interfered with one another, increasing code complexity and making it difficult to add new parsing methods. I then drew inspiration from compiler design and built an Abstract Syntax Tree (AST) parser for Markdown, accompanied by abstract classes for rule definitions, a rule executor, and a printer to flatten the tree structure back into a string. With components decoupled and testing separated, it allowed for better development, testing, and functional expansion.
After introducing the AST structure, the overall conversion capability was significantly enhanced, making it quite simple to derive various other file types from Markdown. Taking advantage of this, I added a push feature for WeChat Official Accounts: referencing an existing open-source project, I converted Markdown into HTML with inlined CSS for rich-text pasting into the clipboard. During this process, images are embedded as base 64 strings, eliminating the dependency on external image hosting.
Building on this foundation, I added some “dessert” features: Git query and push functions, a differential translation feature dependent on git diff, and batch export capabilities. The final result feels quite good to me—at least, it is more than sufficient for personal use 😄.
It is worth mentioning that before writing the plugin, I seriously considered whether I could create a GitHub open-source project to publish Obsidian notes as a webpage. For this, I conducted a comprehensive investigation: Notes-to-Blog Research Report.
Ultimately, I found that Quartz was incredibly feature-rich—essentially a web-based version of Obsidian—and its style was among the most attractive in its category. However, precisely because its interface was so similar to Obsidian, I felt such a layout was better suited for a knowledge base site. The logic was roughly: the knowledge base contains rough notes, which are then summarized and distilled into refined blog posts. Therefore, I embedded a small link in my original Hugo blog to jump to this knowledge base page, looking something like this:
Of course, I haven’t used this knowledge base for a long time now. I realized I don’t really need the step of “distilling rough notes into refined blog posts”; I prefer writing long-form blog articles directly. Furthermore, since I wasn’t that familiar with Quartz, its CLI interface has faded from my memory. In a way, this was another instance of trial and error.
Ubuntu Launch #
I decided to try Linux as a native OS, thinking it might be more stable than WSL. I documented the journey in Ubuntu Tinkering Notes. I learned about file hierarchies, shell RCs, and the ancient art of Vim. My guiding principle: simple usage, complex config, maximum performance.
There’s a unique feeling when a computer does exactly what you tell it to do. I call it “understanding the principles just enough.”
I didn’t intend to make Ubuntu my main OS, but I slowly found myself staying there longer. Windows always felt… “stuttery.” You don’t notice it until you have a comparison. Ubuntu felt like a “driving experience”—light, responsive, and exhilarating.
The Undergraduate Innovation Program #
Dachuang, refers to the Undergraduate Innovation and Entrepreneurship Training Program, which combines scientific research with entrepreneurial training. Simply put, it involves taking a project from a mentor and using it to enter competitions, eventually obtaining project certification through several defenses over the course of a year.
During this semester, I also joined a professor’s lab to try my hand at a “Dachuang” project. Briefly, the project focused on spatio-temporal disease prediction. However, I wasn’t the team leader, and I personally felt the foundation was quite unstable: the data volume was too small (only a few thousand entries), the training targets were ill-defined, and the technical roadmap was unclear. It felt truly difficult to move forward. The most problematic issue was the data size; as is well known, deep learning models are “data monsters,” and it is very hard to achieve good results without massive amounts of data for pre-training. Consequently, during the proposal defense, this point was the most criticized: how can you train a model without sufficient data? This question was incredibly difficult to answer; no matter how one argued, a few thousand entries seemed pitifully sparse 😓. As a result, this Dachuang project failed even to pass the initial proposal stage.
Thoughts from the present
This project could be modeled as a “distribution sequence to distribution sequence” prediction, very similar to a standard Transformer, and could be trained using the Teacher-Forcing approach. But data volume remains an unavoidable Achilles’ heel. The problem of data volume has always existed, and in recent years, it has become even more absurd—the data of the entire internet is now just the baseline for today’s LLMs. From a certain perspective, this is indeed a question worth pondering: how can we improve data efficiency? Or, more comparatively: why don’t humans need that much data for training?
From this failed Dachuang experience, I also felt a sense of confusion: even algorithms that seem so perfect in theory still encounter problems in practical application. But looking at it from another angle, perhaps only through actual use can one discover real problems. Therefore, during the winter break, I planned to use LLMs extensively for coding and learning, accumulating practical experience with LLMs to understand what the current LLM-driven ecosystem really looks like.
Schedule Management & AI4Coding #
Over the winter break, I tried to solve a personal problem: I had too many things to do (papers, classes, coding, gym) and my brain was tired of managing the schedule. I wanted an AI assistant to handle it.
Since I was eager to try “AI-driven coding,” I jumped into development using Electron without a clear plan. I didn’t even understand the concept of a backend yet; I just knew I could call an API.
Hindsight
I made a classic mistake: no requirement analysis, no success metrics. I tried to cram every feature into the “Assistant,” hitting the ceiling of current LLM capabilities. AI is actually quite bad at handling complex, preference-based scheduling, and the token cost was astronomical.
I ended up with a basic desktop chat app. I learned that while AI is great at writing code, its knowledge is often outdated. It forgets context, makes “hallucinated” mistakes, and requires constant human intervention.
Note
The solution today is “Vibe Coding” frameworks that constrain LLM uncertainty. If you provide clear testing methods and a high token budget, LLMs can build almost anything. I used to think LLMs shouldn’t need “frameworks,” but now I see that engineering scaffolding is the only way to make them useful in the real world.
Switching Research Groups #
Winter break hurried to an end, and the new semester brought a course load significantly heavier than the last. The time available for exploration dwindled accordingly; after all, energy is a finite resource.
The first major decision I made this semester was leaving my previous mentor’s lab to join my current research group. My previous mentor was a rising star in the database field—serious, responsible, and possessed of an excellent academic background and network. He had a vast number of undergraduate and graduate students, often filling the meeting room to capacity during group sessions.
Initially, my sole reason for joining that lab was to participate in a “Dachuang” project: a classmate had invited me to join her team, but the project required all members to belong to the same lab. So, I joined. To be honest, I had no passion for databases or data mining. My attention was entirely fixed on LLMs, particularly frontier model and algorithm design. Furthermore, because that mentor was so famous and the lab was teeming with talent, it was a classic case of “too many monks and not enough porridge.” My daily tasks consisted of trivial and simple database maintenance which had little to do with LLMs—it was quite draining.
Upon hearing of another professor working on LLM-related research, I “jumped ship” to my current mentor’s group to produce academic results as efficiently as possible. This mentor is a junior academic (a so-called “academic green pepper”), making communication much easier; he understands exactly why undergraduates are so anxious to produce results.
Helplessness 😮💨
Some professors might feel that today’s undergraduates are too “flickery”—rushing for success and results without the patience to do solid research. However, I believe this isn’t a choice made by individual students, but a reflection of the severe “involution” in our current environment. If you don’t pursue efficiency and output, you become extremely vulnerable at critical junctures like the graduate school nomination process: the gap between vague talk of “research literacy” and a solid CCF-A paper is self-evident. Moreover, looking at the info on a certain “red social app” (Xiaohongshu), most successful candidates have a few papers under their belt, with some high-achievers even having five or more. Therefore, I believe the undergraduate rush for results is not an individual choice, but a concrete manifestation of environmental pressure—essentially: there is no other choice.
In short, after switching research groups, my objectives became much clearer: accumulate academic output. Cutting out most ineffective actions and heading straight for the goal to achieve end-to-end task execution is the essential survival skill of the moment. Younger professors tend to understand this point better.
Computer Design Competition #
Of course, before truly embarking on my research journey, I needed to put the coding experience accumulated since winter break to the test: I decided to enter the Computer Design Competition with my half-baked project.
Looking back, it was a truly chaotic time. Since we were building from scratch, I saw the balcony of Huxi at 3:30 AM more times than I can count.
First was the general conception of the software. As mentioned, I hoped to use an LLM to create something akin to a personal schedule assistant. I must say, this was an exceptionally grand vision—a fact I didn’t realize when the project began.
First, the software needed to extract schedule information, habits, and preferences from user dialogue. This involved key information extraction, storage modeling of complex schedules, serialization and deserialization, preference loading, and reference association. To put it more bluntly: our software needed to record user schedules and preferences during interaction. But how to store schedule info? How to store preferences? When a user mentions a specific event, how to accurately link it to the data store? How to associate the right preference? These questions alone are both low-level and far-reaching.
To model user needs more clearly, I even launched a small-scale questionnaire on campus, collecting various questions users expected to ask this schedule assistant.
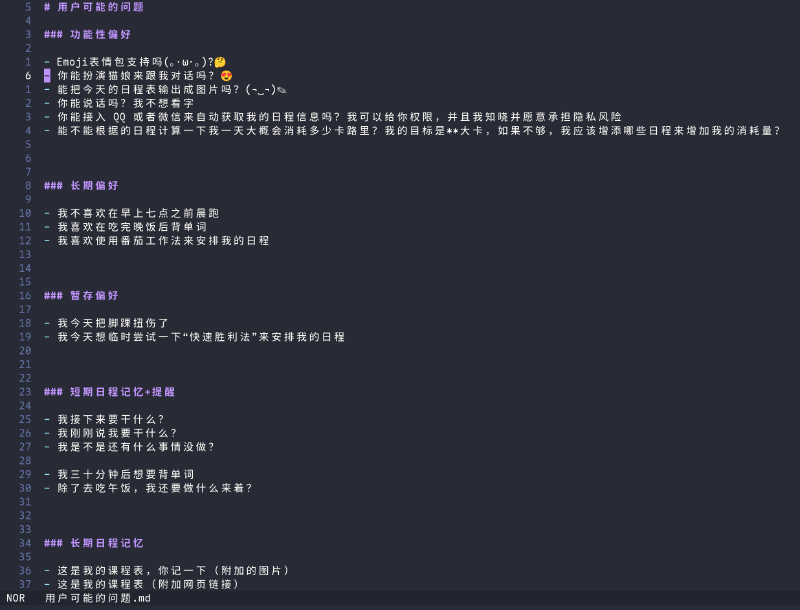
It turned out some questions were quite difficult to answer. Supporting so many functions perfectly would require an incredibly complex underlying data pipeline. Moreover, a major hurdle for LLMs lies here: response speed. While dozens of tokens per second isn’t slow for a simple chat, it becomes a severe issue when you layer multiple nested LLM calls. Therefore, from this perspective, LLM usage should be minimized. But from another angle, to solve these seemingly simple questions, is there any better way besides LLMs? Apparently not. Thus, the first principle was: limit the LLM call structure to at most two layers and implement system-level asynchronous concurrency to reduce response time while maintaining generality.
So, my roommate and I began designing the backend data pipeline. After long iterations of the tech stack—three times in total—we finally decided to use PocketFlow, a concise asynchronous framework, to build the Agent. We used a vector database and a relational database together to store user schedules, supporting both fuzzy semantic search and precise relational queries. The architecture featured one Manager and three Sub-Agents, with all dialogue messages recorded in a public memory space where each Agent viewed messages through a “filter” to avoid context window explosion.
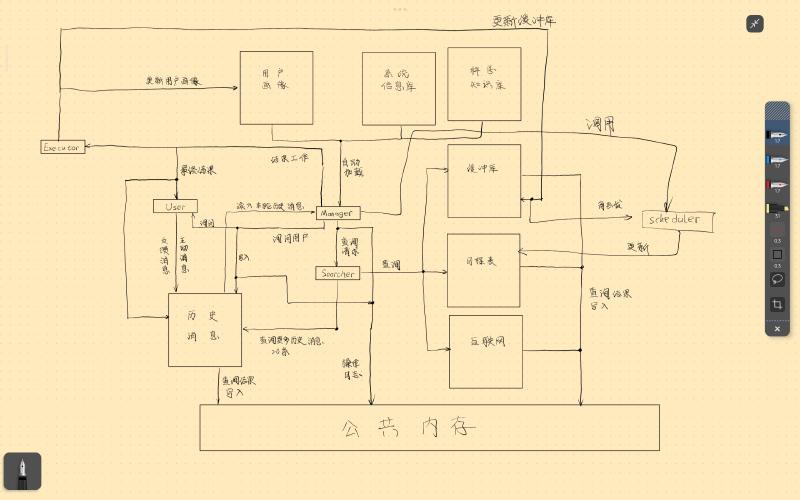
The resulting data pipeline was truly complex. PS: This diagram honestly gave me psychological trauma; I don’t ever want to look at it a second time. It feels like being strangled by a giant python. 😵
Beyond the brain-burning task of system design, there were even more time-consuming matters: code development and deployment. This was divided into three parts: frontend, backend, and server deployment. Every single one was a hard nut to crack. 😭
For the frontend, to quickly build a usable page, we used a template written by someone else. How should I put it… it seemed to save UI build time then, but the time spent handling data passing actually increased. At the time, I knew almost nothing about the React and Vercel ecosystems, and looking back, that frontend code was atrocious. It made the frontend workload extremely heavy, and in the end, we barely managed a functional web chat interface. The frontend code was a textbook “sh*t mountain.”
Heartfelt Voice
You know nothing of “sh*t mountains” until you’ve written one yourself and struggled through it. 😭😭😭😭 It was pure, heart-wrenching agony… Don’t give me that “as long as it runs” line; I was nearly choked to death by the code before it even ran.
The backend primarily involved implementing that complex data pipeline, where asynchronous programming and WebSockets further added to the difficulty. Parts involving LLM operations were especially hard to debug; weaker models performed poorly under complex prompt conditions. Thus, to adapt to more models, I had to repeatedly emphasize formats, operations, and output specifications in the prompts. Although it looked complex, it was fundamentally understandable, and the minimalist PocketFlow Agent framework helped solve some tedious issues.
Then came server deployment. Generally, we used Docker for containerization, but the actual process remained exceptionally tedious and time-consuming. See Deploying Services on Cloud Servers for details, where I recorded mostly cloud-server-related issues; you’ll see how fragmented the operations were. Yet that was only part of it. Building Docker containers was a chore: you had to wrap the Qdrant vector database and MySQL relational database, build internal network communication between modules, use Nginx to expose ports externally while using Certbot for automatic SSL certificates, and handle frontend CORS issues.
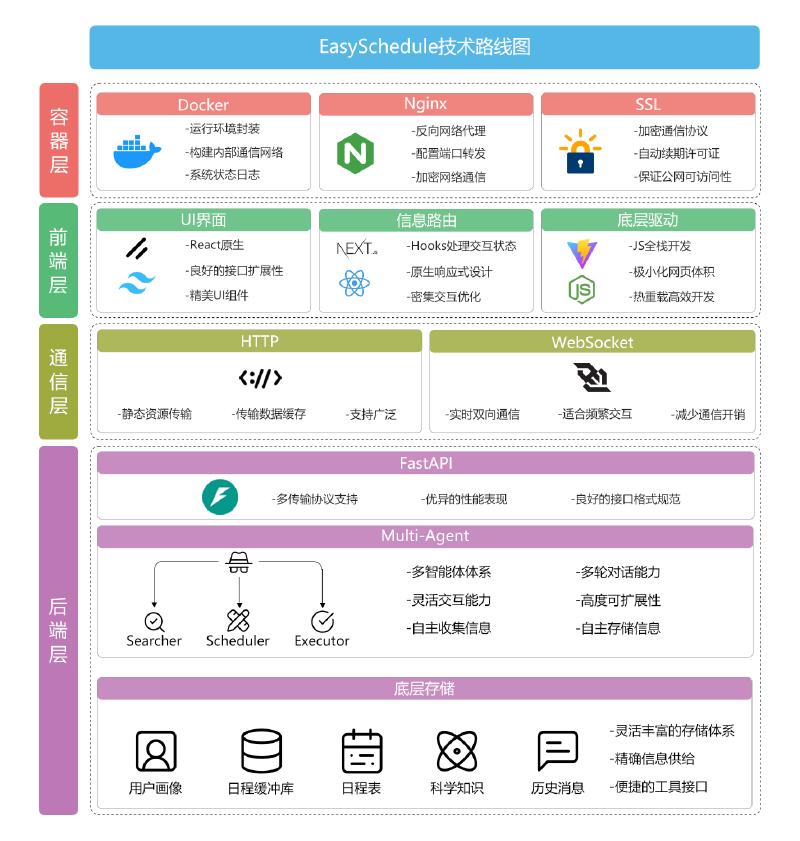
Finally, after solving all the above, we got the final personal schedule assistant. I hate to admit it, but the end result was… underwhelming. 😭 Despite the async concurrency, the response speed was still slow. Though it could basically achieve our envisioned effects, hidden bugs and instabilities cropped up constantly. The prompts, despite heavy tuning, were bloated and required strong models to drive them (weak models failed to execute correctly)… In short, it was far from my expectations. The final competition result was also bare-bones: just a Provincial Third Prize, essentially a participation award. 😭
From this experience, I clearly realized: effort doesn’t necessarily yield good results; direction is more important. That is to say, if one wants to achieve a truly meaningful personal intelligent assistant, this kind of engineered “Context Engineering” can hardly reach production-grade effects. In the field of AI 4 Coding, there is clear and effective software engineering theory to support us; we can construct an effective Context, AI can easily edit code text, and compilers or test suites can verify code quality to keep the Context clean.
After understanding the development of AI 4 Coding, I suddenly realized that a truly effective Agent might not need so many fancy data pipelines and tools. Perhaps an appropriately sized Markdown file for storing important memories is enough—even reaching the current ceiling of what LLMs can do. To go further, one would need a breakthrough in underlying models: we need a model that can truly learn continuously, compressing information into network weights. After all, weights can store far more information than a Markdown file, and one wouldn’t need to worry about “searching” for info—a single forward pass would solve it.
Thinking
Truth is simple; no words needed. Simplicity and effectiveness are a form of decision-making aesthetics.
Software Practicum #
Our task: build a Smart Home System in 14 days (Frontend + Backend + Hardware). We used MQTT for hardware and a mix of HTTP/WebSockets for the rest.
With my previous modeling and full-stack experience, this was a breeze. We hit every milestone early. Our team was eerily quiet—no arguments, no procrastination. We just… worked. It felt like we had been colleagues for years.
The only regret: no celebratory dinner. Everyone was busy. My strongest memory of that time is walking down the middle of an empty road at midnight, the humid Chongqing air making everything feel slightly surreal.
Campus Network Remote Access System #
To enable remote access to the computing servers within the campus intranet, I decided to build a campus network remote access system myself. At that time, I hadn’t yet studied computer networks; I completed this system in a single day, almost entirely with the assistance of AI.
I tried many methods back then, such as using frp for NAT traversal and Tailscale for P 2 P direct connections. However, as is well known, both carrier-grade NATs and campus networks are extremely difficult to penetrate; for this reason, Tailscale’s P 2 P direct connection also failed (it could only route through overseas relay servers, resulting in extremely high latency). Ultimately, I chose to use WireGuard and leverage a public cloud server to establish a reverse connection to an industrial PC (jump box) within the campus network, finally enabling bi-directional communication under such difficult circumstances.
graph LR subgraph "Outside" User["💻 Remote User
(WG Client)"] end subgraph "Cloud (Relay Node)" Cloud["☁️ Public Cloud Server
(WG Server / Hub)"] end subgraph "Campus Network" Jump["📟 Jump Box/Gateway
(WG Client)"] Target["🚀 Compute Server"] end User <== "Encrypted Tunnel" ==> Cloud Jump -- "1.Initiate Connection" --> Cloud Cloud <== "2.Establish Bi-directional Tunnel" ==> Jump Jump -. "3.LAN Forwarding" .-> Target style User fill:#e1f5fe,stroke:#01579b style Cloud fill:#fff3e0,stroke:#e65100,stroke-width:2px style Jump fill:#f3e5f5,stroke:#4a148c style Target fill:#e8f5e9,stroke:#1b5e20,stroke-width:2px
To briefly explain what a reverse connection is: current firewalls and NAT systems generally block unsolicited incoming traffic from the outside. However, if a request is initiated from the inside, the corresponding response traffic from the outside can enter the internal network at any depth with almost no resistance. After all, if responses to internal requests were blocked, it would be no different from being disconnected from the internet. By exploiting this characteristic, a client deep within the intranet can actively access a public server and use heartbeats to keep the connection alive, easily establishing a bi-directional tunnel. Since the data receiver initiates the connection to receive data, it is called a reverse connection.
The only downside is that the public cloud server costs money 😅; everything else is virtually impeccable: an extremely low latency of 20 ms, exceptional stability (able to handle intermittent campus network logouts, power outages, etc.), ease of use, and powerful functionality (it can even act as an HTTP proxy when paired with Clash).
Note
Theoretically, double-sided symmetric NAT hole punching is possible, and there are even several software tools capable of this (EasyTier and OpenP2P). Both use “birthday attacks” to penetrate such difficult NATs; while theoretically feasible, the success rate in practice is low, and the traffic behavior closely resembles a DoS attack, which might lead to a MAC address ban 😢.
Junior Year #
Joining the Arch Cult #
After tinkering with Ubuntu for nearly a year, various more novel Linux systems gradually entered my field of vision. For example, Mint is said to be the most popular system for beginners, Fedora is the choice of Linus Torvalds (the father of Linux), and Manjaro, derived from Arch, provides a graphical installation interface and stable software repositories. There is even SteamOS, which, as its name suggests, is born for Steam gaming 🐸.
Since my pursuit is extreme performance, high customization, and the latest software experience, I ultimately chose Arch Linux—rumored to be the most minimalist yet hardest-to-master Linux distribution, and said to be somewhat unstable, occasionally crashing due to rolling updates. Because people who “fall into the pit” often find it hard to pull themselves out, it has been dubbed the “Arch Cult.” With so many labels stacked on it, my curiosity was piqued; I really wanted to see what this so-called “monster” was all about 🤔. Thus, in the middle of the first semester of my junior year, I resolutely set aside three days to tinker with it.
Following the Arch Linux Brief Guide, I began my Arch journey. This guide is extremely detailed, especially regarding low-level configurations like networking, file systems, and system bootloaders.
After this “smooth combo” of operations, congratulations! 🎉 You finally have a black command-line interface. Yes, after all that work, you haven’t even installed a graphical interface yet. It took me nearly a day and a half to get to this point, and that was with my prior experience with Ubuntu and some understanding of Linux systems; I can’t imagine what it would be like for a complete beginner. Therefore, I reiterate a common warning found online: Arch Linux is not recommended for beginners 😢.
Then, for the installation of the Graphical User Interface (GUI), I stopped following that tutorial. This was because even before installing Arch, I already had my heart set on one: the niri desktop compositor. Here is a large image from the official GitHub 😁. In short, niri is an infinite-scrolling tiling window manager. I had previously looked into Hyprland and other tiling managers, but I personally disliked the approach of forced window compression; niri, however, perfectly hit my core vision for a tiling desktop—elegant, concise, efficient, and beautiful.
Mood 😄
It was truly love at first sight with niri. Just as you are mentally modeling the problem of tiling window management, a solution appears that perfectly fits your train of thought.
So, I opened Google AI Studio and the Arch Wiki on my phone as assistants and began the journey toward the niri desktop environment. Of course, once the underlying file system and other configurations are done, installing the desktop environment is simple: just use pacman to install it. The tedious part is the adjustment of other desktop components and configuration files: the status bar, desktop wallpaper, login manager, input methods, and so on. The final result of all that tinkering was a clean and efficient Arch desktop system.
Next came various choices and optimizations regarding user experience—countless small tools and system tuning. Most of the important, reusable content has been merged into Ubuntu Tinkering Notes, so I didn’t create a separate blog post for it. Additionally, I referred to experiences on YouTube to build a dotfiles repository to facilitate configuration management and migration.
Thinking
At first, I didn’t understand what “dotfiles” were; I saw the term many times but paid no attention. It wasn’t until I saw it too many times that I got curious, and then I unlocked a very useful configuration management tool. This kind of accidental encounter is one of the great joys of Linux.
In the days that followed, I completely switched my primary operating system to Arch Linux. This “rough stone” of an operating system was polished like a pebble—becoming smoother and smoother, and more and more aligned with my vision of a perfect OS: concise, efficient, easy to manage, and smooth to use. I finally understood why Arch is a cult: even the most exquisite mass-produced industrial product cannot compare to a hand-crafted piece of art that iterates through its own use. People feel a resonance with things born from their own hands and their own choices.
Thinking
Next-generation consumer hardware should achieve something similar. Hardware starts depreciating from the moment it is sold, but the data settled in time actually holds high value; hardware should capture this value. This process is very much like panning for gold within information streams.
Furthermore, once you have such a versatile tool, you can easily solidify knowledge into small utilities. For example, the ssh reverse proxy tool allows every server I can SSH into to conveniently access the external network; a watchdog tool helps me monitor the running status of long processes and send WeChat notifications; and an mping tool monitors my mailbox and sends a WeChat notification when I receive reviewer comments. The significance of these inconspicuous little things lies in transferring the trivial work that requires your energy to maintain over to the computer—tireless and reliable.
That is the entirety of my Linux tinkering. No world-shaking achievements, just iterative optimizations accumulated bit by bit. I am occasionally asked why I use Linux, with the viewpoint being: since Windows can do everything, there is no need for Linux. I admit this is a fact—current mainstream operating systems are almost identical in functionality, with the only moat being the software ecosystem. But my reason for using Linux is simple: I just wanted to try “another solution.” It was pure curiosity. Initially, I had no intention of making Linux my primary OS, but after tinkering for a long time, I found that I prefer the freedom and efficiency of the Linux ecosystem. Compared to the intuitiveness of a GUI, I prefer the conciseness of the command line; compared to mere usage, I prefer exploring the principles. All in all, Linux is just an option—I chose this option through practical experience and quite enjoy it. That’s all.
The Knowledge Graph Paper #
After completing the software practicum, I almost immediately plunged into my paper experiments. Although I also set up the campus network remote access system and tinkered with Arch Linux along the way, the bulk of my energy was truly dedicated to the paper.
The background of this paper is addressing the sparsity problem in Knowledge Graph (KG) reasoning. Simply put, certain entities in a KG have so few associated edges that reasoning performance suffers (resulting in low MRR scores). Thus, we proposed a KG reasoning framework to alleviate this issue (a problem that seems impossible to “solve” entirely, only to mitigate).
The context when I started was: a senior student had already done some preliminary work and established the main theme of data augmentation, and then my mentor suggested the idea of using MCTS to solve the problem.
From there, I began the constant iteration of the core algorithm. Initially, I tried using an LLM as an Agent to “wander” around the knowledge graph, but upon reflection, the time cost was too high and the results weren’t necessarily guaranteed. So, I began analyzing the problem from first principles: the core question is, how do we add new relations to sparse entities?
Obviously, the most brute-force approach would be to take a sparse entity as a head or tail entity and pair it with every existing relation and every other entity in the KG. The advantage is that, theoretically, this is the ceiling for sparse entity augmentation (all possible relations are included); the disadvantage is that the noise is off the charts.
I then considered introducing a high-quality triple discriminator for validation, which led to a second problem: the higher the discriminator’s accuracy, the longer it takes. LLMs are the best as triple discriminators, reaching nearly 75% accuracy, but the calling costs are astronomical. If an LLM discriminator were to brute-force search every possible combination, it would take an estimated 370,000 hours—clearly unacceptable.
To solve this, I introduced MCTS to balance exploration and exploitation, avoiding the brute-force search. However, noise still exists in the newly added data. To further reduce the impact of noise on training results, I utilized the ideas of adaptive message aggregation and large-loss suppression.
Indeed, the logic of the entire paper is very clean, without bloated modules. I consider it a great practice of first principles. The final results were also quite good, with an MRR improvement of 18% and 16% over the best baseline across two datasets. This is the paper’s biggest selling point, and it can be considered a new SOTA.
Thinking
Looking back after a paper is done, it feels quite simple. But when you are in the thick of it, things aren’t so clear—you either can’t trim down your various ideas or you get stuck in a dead end. In short, writing a paper is really not easy 😓.
Naturally, following the mindset learned from Arch Linux, I also tried to model an AI-assisted scientific research framework. I attempted to model a complete research process as a tree structure—from reading literature and organizing ideas to algorithm implementation and benchmarking. Every critical decision is a branch point; some branches can be pruned early, while others require clear experimental results to judge. From this perspective, research transforms from a game of luck into a pure search and verification problem. Does this large-scale search and verification problem sound familiar? 😁 Yes, exactly—AlphaZero. The research process can almost be mapped directly into the shell of Go, where an LLM can drive the entire “research flywheel” continuously. The only problem is: how to let the AI continuously learn from a vast amount of research experience? To be honest, I’ve encountered this issue of continual learning more than once; it feels like the “Sophon” from The Three-Body Problem.
Coincidentally aligning with my thoughts is the recently viral FARS: capable of pumping out papers at a rate of one short paper every two hours. Combined with the AI peer-review system led by Andrew Ng, it has reached the average human level in evaluations. This is truly a good thing; it signals that scientific research is entering the era of industrial mass production. Moreover, this could completely end the “obsessive focus on paper count”: when FARS can churn out short papers every two hours, how much significance does the sheer number of papers still hold? It’s worth pondering.
Of course, we haven’t reached the era of true mass production yet, so the metric of paper count still holds some reference value for now. But after all, there isn’t much time left for humans to “hand-craft” papers using traditional methods. Cherish it while you can 🐸.
The Future #
I want to solve Continual Learning for LLMs. This “mysterious threshold” has appeared in every real-world problem I’ve faced. If we cross it, we are much closer to AGI.


