

前言 #
现在的大模型技术发展可谓是"日新月异",好像每天都有令人震撼的重要进展🤔
事实上,这些"重要进展"到底有多有效?工程实践上的价值到底有多少?这些问题最终还是要回到那些"平凡"的经典知识上。
关注大模型技术最新的进展当然是好事:这有助于我们了解研究方向,开拓思维。但是不能只关注那些不断发展的顶层技术,还要关注那些发展背后的、底层的、不变的东西。
这也是在这个技术突飞猛进的时代,沉下心去阅读教材的意义所在。
本篇主要关注浙大编写的 《大模型基础》一书,这本书目前还在不断更新中。
语言模型基础 #
这部分内容就是目前大学中最常教授的知识内容:基于 n-grams 的统计学语言建模,基于 RNN 的语言模型和基于 Transformer 的语言模型。下面贴一张 Transformer 架构的流程图。
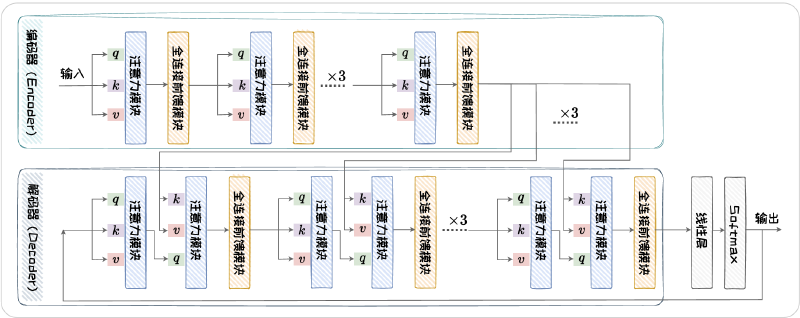
模型架构没什么好说的,但这里有几个比较有意思的问题,在我看书之前还比较模糊,看书之后就立刻清晰了。
Q:都说 Transformer 是并行计算的架构,但为什么还是只能一个 token 接着一个 token 串行生成?
A:Transformer 的并行计算体现在处理已知序列上,所有已知的 token 的向量会被并行地送入模型中进行处理。Token 的生成过程还是串行地自回归地生成。
Q:将残差连接和层归一化的顺序调换对模型有影响吗?
A:将层归一化放在残差连接后面的网络叫做 Post-LN,还有一种将层归一化放在残差连接之前的网络叫做 Pre-LN;Post-LN 应对表征坍塌的能力更强,处理梯度消失的能力略弱,Pre-LN 反之。
Q:表征坍塌是什么意思?
A:在训练过程中,模型学习到的表示变得缺乏区分性,也就是说不同的输入样本被映射到相似甚至相同的特征向量,导致模型失去了对于不同样本的判别性。
Q:为什么 Transformer 的 Encoder 部分和 Decoder 部分可以单独构建语言模型?
A:通过后文对 主流架构 的介绍,可以发现只有 Encoder-Decoder 和 Decoder-only 架构才能够单独构建我们印象中的能够流畅生成文本的"语言模型",而 Encoder-only 的架构其实是很局限的,一般用于产生文本的嵌入表示。
Q:Transformer 模型训练时使用的损失函数是什么?
A:不同类型的训练任务有不同的损失函数,在自回归预测任务中,损失函数与传统 RNN 模型一致,就是模型预测结果与真实答案的交叉熵。
Q:top-k,top-p 和 temperature 是什么东西?作用是什么?
A:top-k,top-p 和 temperature 都是语言模型解码为文本过程使用的参数。但三者的意义并不等价,top-k 和 top-p 都是采样方法,而 temperature 则是调控采样的随机性。
模型的解码分为两种,一种是概率最大化方法,即解码出概率最高的文本段;另一种是随机采样的方法,能够让模型生成的文本更有新意。
在随机采样中,使用参数的不同就对应了不同的采样方法,即 top-k 采样,top-p 采样。top-k 采样限定了解码的候选词的数量(选取概率最高的 k 个候选词),而 top-p 限定了候选词的概率(选取概率高于 p 的候选词)。整体而言,top-p 的效果更好,因为 top-p 可以避免选中某些概率很小的词,避免模型胡言乱语的现象;也可以提升模型输出文本的丰富程度,特别是在候选词概率较为平均的情况下,能够囊括更多的候选词。
temperature 是对 softmax 函数中自变量的尺度进行变换,并利用 softmax 函数的非线性实现对于采样随机性的调控。在 top-k 和 top-p 采样过程中,会从字典中选出部分候选词,这部分候选词的概率需要使用 softmax 函数来归一化。而 temperature 机制就是在候选词原有的概率基础上除以 temperature 参数T。当 \(T>1\) 时,不同候选词之间的差异变小,模型的随机性更大,反之同理。
大语言模型架构 #
扩展法则 #
扩展法则(Scaling Law)揭示了模型的能力随模型和数据规模的变化关系,为大语言模型的设计和优化提供了宝贵的指导和参考。
使用广泛的有 OpenAI 提出的 Kaplan-McCandlish 扩展法则,DeepMind 提出的 Chinchilla 扩展法则。后者是在前者基础上进行的进一步探索。
$$ L(N,D)=E+\frac{A}{N^\alpha}+\frac{B}{D^\beta} $$$$ E=1.69,A=406.4,B=410.7,\alpha=0.34,\beta=0.28 $$其中 \(L\) 表示交叉熵损失函数,\(N\) 表示模型参数规模,\(D\) 表示训练所用的数据量
另外,在计算总量 \(C\) 给定的条件下,最优的模型和数据规模分别是:
$$ N_{opt}\propto C^{0.46}, D_{opt}\propto C^{0.54} $$主流架构 #
主流的架构分为 Encoder-only,Encoder-Decoder 和 Decoder-only 架构
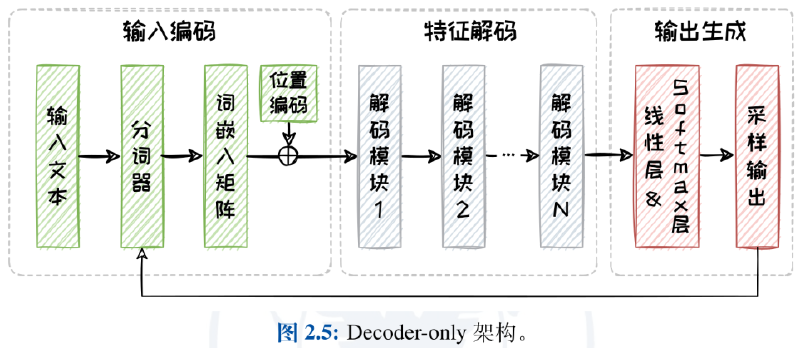
Encoder-only 架构直观上真的就只有一个编码器,其中特征编码部分包括了自注意力层和全连接层。一个非常自然的问题是:只有编码如何训练?实际上,在预训练过程中使用一个全连接层将编码转换为掩码预测任务,在处理实际任务的时候需要另行定制专门的任务处理层
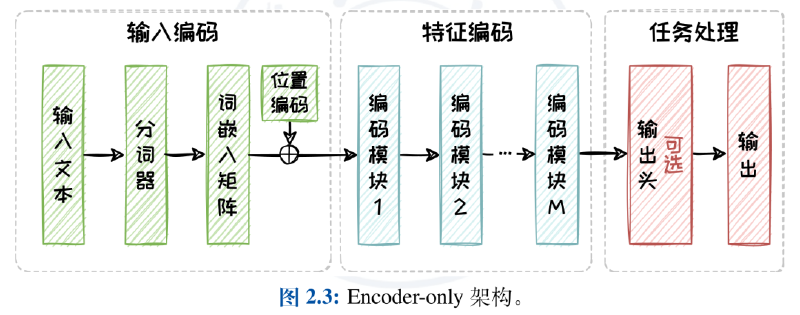
Encoder-Decoder 架构是非常标准的 Transformer 结构,在训练阶段使用输入和真实输出(Ground Truth)进行训练:首先输入文本被编码为向量序列,然后在特征编码器中被转化为内部上下文特征;在解码器部分使用 Teacher-Forcing 技术,使用真实输出中的已知部分作为输入并结合从编码模块得到的输入上下文来预测下一个 Token 然后计算损失,通过反向传播更新模型参数
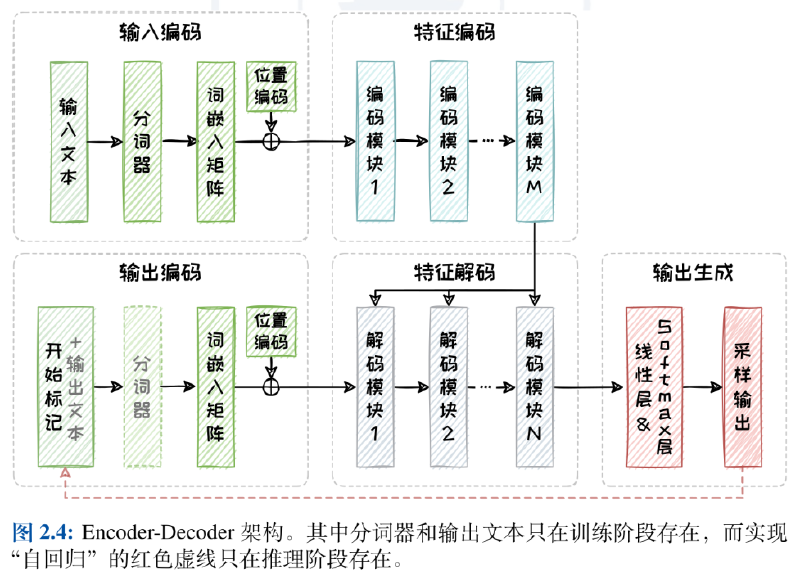
Decoder-only 架构出现的原因是:有效缩减了模型的规模,降低了整体的复杂度;与之前类似,在训练阶段这种架构同样首先将输入编码为向量组,然后使用 Teacher-Forcing技术进行自回归训练(将输入文本与真实输出的已知文本拼接逐步训练)
三种主流架构功能对比 #
三种架构在注意力矩阵上有很大的差别,因此也决定了这三种架构适用于不同的任务;如下图所示,Encoder-only 架构中的注意力矩阵呈现出完全的注意力形态,也就是双向注意力,在这种注意力下能够建模复杂的语义联系与上下文依赖;Encoder-Decoder 中输入部分为双向注意力,而输出本分为单向注意力,后一个 Token 只关注前面的 Token;Decoder-only 架构中的注意力来自掩码自注意力模块,预测当前 Token 时只能够依赖历史生成的 Token,是完全的单向注意力

综上所述,Encoder-only 适合自然语言理解任务,如情感分析、文本分类等判别任务,但在自然语言生成任务上可能不如其他两种架构;Encoder-Decoder 架构适合有条件生成任务,如机器翻译、文本摘要和问答系统等需要同时处理输入和输出的场景,但是新添加的解码器同样带来了计算规模庞大的问题;Decoder-only 架构适合无条件文本生成任务,能够生成高质量连贯文本,在自动故事生成、新闻编写等不需要特定输入文本的任务;但是在规模有限的情况下,Decoder-only 架构对复杂文本的理解存在局限性,表现可能不如 Encoder-Decoder 架构
这里对于Decoder-only架构的局限性的描述措辞其实比较微妙,必须要在规模受限的情况下,Decoder-only 才比 Encoder-Decoder 的文本理解能力更差;但是 Decoder-only 凭借更加出色的任务泛化性,成为了目前最主流的架构


